End-to-end release times are 40% faster
tl;dr
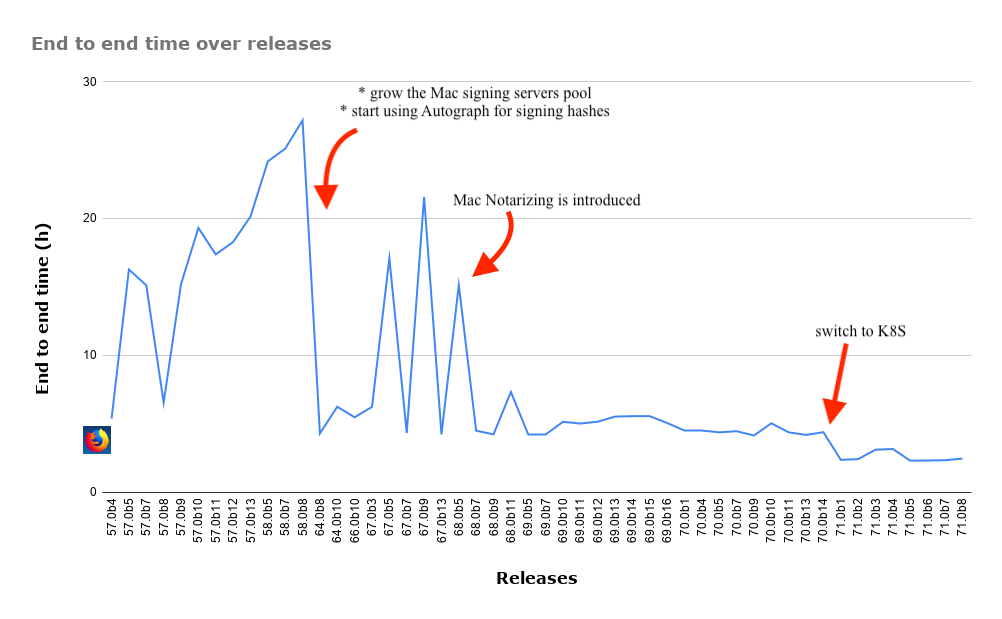
End-to-end release times are now 40% faster. And we are not stopping here. The joke in RelEng has traditionally been that we would like to get to one-hour-releases. Well, it is safe to say that is no longer a joke but a tangible goal in the near future.
Context
Historically, the Release Engineering team’s mission has been to automate ourselves out of a job, preferably in a timely and reliable fashion. To better put it: no manual steps while shipping fast and often. As such, one of the metrics that we have always kept on the radar is end-to-end release times: the sooner we are able to put the release artifacts in QA’s hands for testing, the better it is. This metric is best reflected during the process of shipping critically important updates of our browser, when time is a critical aspect.
Over the last decade we migrated through different CI/CD systems and frameworks and with each migration we have improved our end-to-end times, decreasing from weeks to a number of hours.
Within the migration to Taskcluster, we stabilized our standard release time for a beta (which is what we usually take into account for a reference) to an average of 5h15’.
With the recent work in coupling auto-scalable Kubernetes and tagging along GCP underlying infrastructure and a handful of other improvements, we managed to reduce the end-to-end times by 40% to around 2h40’.
Worth mentioning that handing over the release into QA’s hands takes even less than that, but this metric includes our automatic update verification system, which to this day, remains expensive.
We are not stopping here though. There are more improvements to make and we are to better learn how to configure the autoscaler in Kubernetes to minimize the costs and maximize the time efficiency; our hope is that we can get these numbers even lower.
Given that we are going to switch to daily betas in the near future, these improvements should come in handy.
Strategy
In order to reduce our release time we explored a handful of avenues. Some were successful in terms of reducing our end-to-end times, others in reducing the overall load for a specific worker, while others were simply good for cleanup. Going forward are some of the strategies that we considered.
Migrate to auto-scalable infrastructure
Upon completing the migration to Taskcluster as our CI/CD, we relied on dedicated scriptworkers
(the special worker type we use for serving our release pipeline) instances in AWS cloud.
We had a fixed pool for each of these workers. Ramping up new instances, though straightforward as a process, could have taken up to a few hours and was partially blocked on other teams.
Moreover, at times we experienced, either overcapacity for some of the pools (hence, waste of $$$ since we had fixed allocated AWS instances with static DNS, etc) or
insufficient machines to handle large queues of pending jobs (hence more times in release end to end times).
Coupling auto-scalable Kubernetes and tagging along the underlying GCP infrastructure in bug 1533337 proved to be a big win for us. Not only we can now afford flexible pools of workers, depending on the load, but we can also optimize the costs better since we ramp-up/tear-down pods only when we need them. Using the auto-scalable configured pods, we can easily double our capacity for our prone-to-be-bottlenecks workers (such as signing, beetmover and balrog).
Remove individual checksums-signing
Within our release automation, we used to generate individual checksums files for each of the platform/locale pair that we build, sign and beetmove. Upon signing these individual checksums files, we baked them together in order to create a big checksums file that’s published at the root of the directory for each release (e.g. example). We then signed those aggregated big checksums files in order to ensure downstream consumers that the files haven’t been tampered with. Following-up a conversation we had in Whistler, we concluded we could safely remove the signing for those individual small checksums files, as whoever wants to check the validity of the artifacts, can do so by inspecting the aggregated ones directly.
Removing the checksums-signing kind altogether in bug 1567429 cut ~600 tasks, ensuring a more supple graph and saved around ~10% in the end-to-end beetmover-checksums runtime
(which was the task consuming and transferring the signed individual checksums).
Results from nightly, before and after trimming the un-needed checksums-signing tasks are as follows:
(before) 03h:43’:22’’ <= represents 1.83% of the graph total runtime (~10 days of runtime)
(after) 03h:25’:54’’ <= represents 1.64% of the graph total runtime (~10 days of runtime)
Sleep less between retries
Once we generate the updates, we push the information to Balrog via our balrogworkers. The way this works is based on a download-merge-upload blob mechanism:
provided the number of locales that we have per release (~100) and the number of platforms we ship (6), this usually turns into a race condition when all of them are running in parallel,
which is why we’re using a good automated way to retry via redo.
Playing with the main retry() function configs in bug 1579067 turned out to be useful here. Increasing the jitter, the number of attempts before
giving up and also the max amount of time we sleep in between talking to Balrog ended up saving us 1 hour in balrog total runtime.
For example, comparing 70.0b7 against a previous cycle’s counterpart job, the balrogworkers times were as follows:
(70.0b7) 04h:13’:33’’ <= represents 1.73% of the graph total runtime (~10 days of runtime)
(69.0b10) 05h:22’:52’’ <= represents 1.34% of the graph total runtime (~10 days of runtime)
Not much, but adds up, overall.
Optimize partner repacks priorities
For every release of Firefox, we spin up partner repacks for each of the distribution projects. In the beta cycle we do this starting with b8. Along these, we also generate the EME-free repacks which come with DRM-support disabled by default.
Given that the partner repacks are not part of the standard QA testing, these should not block the release. Hence, within bug 1572102, we decreased their priority in the graph so that we free some resources in order to better handle the more important tasks that are blocking QA.
Audit release artifacts
The way we often depict a release is based on a four-pillar system:
- Build
- Sign
- Upload artifacts to a public location (n.b. we call this operation
beetmove) - Generate and serve updates
Each release that we ship consists of a number of artifacts (e.g. Firefox 70.b9 artifacts) including but not limited to: installer files, associated tests results, MAR files (n.b. Mozilla Archive, they are the updates files), automated-related files, various tools and partner repacks. Most of these files are generated at build time and then passed around through signing and beetmover in their respectively public locations.
One of the first things that we did in late Q2 was to audit all these files to better understand how many of them are actually useful. Trimming some of these would have reduced our network throughput and save some storage room in Amazon S3. Unfortunately - or not? :) - based on the analysis concluded in bug 1530728 most of the files we push are consumed by either automation or downstream consumers, so there wasn’t much we could wipe off.
Conclusions
All of these optimisations proved to be useful in reducing our end-to-end time as the aforementioned figure depicts. Even though the coupling of Kubernetes has had the most definitive role, the other avenues explored were also useful in determining better ways to work with the graph, addressed cleanup and sparked other ideas, at their turn, to optimize further.
What’s next?
There are ways to improve even more in the future. Here are some of the existing ideas:
- Learn to better auto-scale in Kubernetes. Currently we still have scenarios where we ramp-up to max pods and then tear down, only to ramp-up again in a few minutes.
It’s worth investing time to analyze the graph to better grasp where we should make those adjustments to give us even more speed and burn less
$$$ - Reduce times and beefy instances for signing by using less memory
- Chunkify more in the graph. This benefit is two-folded:
- easier graphs to play with
- slight speed improvement given there is less overhead in consuming tasks from the Taskcluster Queue
- Reduce the amount of logging we produce. This is good in order to save
$$$in storage space - Move a subset of l10n repacks to on-push, rather than promotion graphs
- Revisit our Update-Verification system in order to make it faster and part of the artifacts we are providing to QA
Kudos
This project has had a steep learning curve and involved lots of hours of work, debug and timezone roundtrips. Special thanks go to:
- Rail and Rok for starting this project and doing the initial heavy lifting
- Catlee for tackling the tricky bits of signingscript
- Bhearsum and NThomas for valuable contributions in identifying ways to optimize the graph and also to shepard some of the workers over the finish line
- Sfraser and Nthomas for aggregating CI data in order to provide dashboards for end to end release times
- Oremj for providing us support from CloudOps along the process
- Everyone in RelEng who, one way or another, contributed to this project along the way